Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Monitorización en serio. Teoría Fri, 07 Dec 2012
Os ahorro tener que leer todo el post para llegar a esta conclusión: El título es un poco sensacionalista, lo sé. Sigamos.
Uno de los aspectos más consolidados en lo que a la administración de sistemas se refiere es la monitorización. No hay infraestructura razonablemente seria que no tenga un ciento de monitores de carga de CPU, memoria consumida, tráfico de red, conexiones abiertas, .... Y junto a estos tenemos otros monitores, algo más avanzados, que por ejemplo revisan si una sesión POP3 se establece correctamente, usando para ello un usuario/contraseña preestablecidos; o que un una página PHP contiene cierto texto, para lo que se hacen X consultas, también predefinidas, en una base de datos.
Básicamente, esto es lo que hay; aquí nos quedamos la mayoría. Pero, ¿Es suficiente?
Sigamos con un ejemplo más concreto:
Vamos a suponer a partir de ahora que somos los responsables de los servidores IMAP de alguna de las empresas más grandes del sector del correo electrónico, y que por lo tanto tenemos millones de usuarios para los que poder acceder a su correo es, obviamente, fundamental.
Con el gráfico de conexiones establecidas en la mano, sabemos que el patrón más habitual es el siguiente:
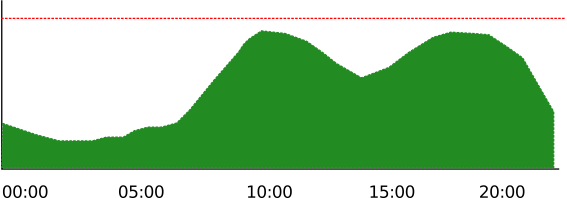
Vemos que tenemos pocas conexiones abiertas durante la madrugada, y que el número va subiendo en la medida en que empieza la jornada laboral, con un pequeño descenso en las horas habituales de comida. Para este ejemplo nos quedamos con esto, aunque en condiciones normales se deberían tener en cuenta fines de semana, vacaciones, ....
La línea roja indica el umbral de alerta del monitor. Ya sabéis: el móvil suena cada vez que la línea verde supere a la roja. Aunque lo normal es que también tuviéramos un umbral de aviso amarillo y otro para cuando las conexiones fueran demasiado bajas, por ahora nos sirve esta versión simplificada.
Y llega el día en el que las conexiones establecidas contra nuestros servidores muestran lo siguiente:
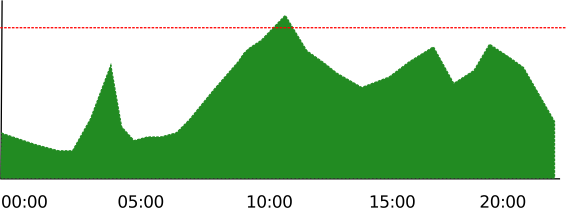
Qué fácil parece todo cuando vemos el gráfico! Lamentablemente, cuando somos responsables de unos cuantos cientos de gráficos, que por supuesto no estamos vigilando constantemente, solo vamos a tener constancia de ese pico de las 10 a.m., que además podría ser perfectamente un pequeño aumento puntual de carga inocuo para el servicio.
Por supuesto, ni nos hemos enterado del ataque por fuerza bruta de las 04:00 a.m. que probablemente haya conseguido "adivinar" decenas de contraseñas de usuarios, ya disponibles para el "spameo" generalizado; o de ese problema de media tarde, que quizá sí haya supuesto una perdida de servicio para muchos usuarios. Pero la cosa es todavía peor, porque resulta que nuestro sistema de validación de cuentas se "volvió loco" justo antes de esa bajada de tráfico y empezó a aceptar logins, independientemente de la validez de la contraseña.
¿Cuántos sistemas de monitorización habéis visto capaces de detectar estas situaciones? Llevadlo a otros entornos: ¿Cuantos sistemas de monitorización concéis capaces de detectar que una tienda online en realidad está cobrando 10 euros menos en algunos pedidos? ¿O un motor de búsqueda que da resultados erróneos periódicamente?
¿Qué hacemos entonces? ¿Tiramos todos los monitores que tenemos a la basura? Obviamenente, no. Es evidente que un servidor con una carga de CPU alta necesita atención.
Sin embargo, lo que sí debemos cambiar es el punto de vista sobre el que gira la monitorización, de tal manera que en lugar de orientarla hacia el aspecto estrictamente operacional, lo hagamos teniendo en cuenta el propio servicio que estamos vigilando, que no deja de ser, en definitiva, lo único que aporta valor. Dicho de otra forma, lo que importa no es que la máquina reviente, sino que el acceso de los clientes falle o sea más lento. Puede parecer un cambio sutil, pero no lo es.
Acercándonos otra vez a la faceta técnica, esto significa que deberíamos prestar más atención a los siguientes aspectos:
- La monitorización debe centrarse en las aplicaciones, y no en el hardware, la red o las máquinas. (Lo que veníamos diciendo sobre la percepción del servicio que tienen los usuarios).
- La monitorización puede ser importante como mecanismo para buscar mejoras y optimaciones para el servicio.
- Desde el punto de vista de los sistemas, esto significa que la monitorización debe interactuar mucho más con las aplicaciones.
- Parámetros como la latencia o el tiempo de respuesta de una aplicación deben cobrar más importancia.
- Detectar las anomalías debe ser uno de los objetivos a conseguir. Dicho de otra forma, si nuestro sistema gana una conexión nueva de media a la semana, y si este lunes tenemos 10, el que la semana siguiente veamos 20 debe alertarnos.
- No se puede monitorizar lo que no se puede medir.
- Por si no ha quedado claro, sólo se puede monitorizar lo que se puede medir.
- Revisar el estado de las aplicaciones hace que algunos de los chequeos "tradicionales" dejen de ser necesarios, con lo que se simplifica la monitorización.
- Los monitores tradicionales siguen siendo útiles para detectar un buen número de problemas, incluidos los relacionados con la escalabilidad de las plataformas.
Pero, ¿Cómo llevamos esto a la práctica?
En líneas generales, necesitamos trabajar mucho más contra los logs que generan los servicios. Si somos los desarrolladores de nuestras aplicaciones (una web por ejemplo), queda en nuestra mano definir y loguear la información que consideramos importante. Si, por el contrario, estamos usando una aplicación de un tercero (el servidor POP/IMAP Dovecot, por citar uno), nos resultará más difícil incluir un logueo específico, pero siempre podremos buscar la información que nos puede aportar visibilidad extra del entorno. En este caso concreto, por ejemplo, el número de intentos de conexión con credenciales inválidas o el ratio logins/logoouts son métricas que nos podrían ayudar en un momento dado, por citar dos.
En cuanto al software que podemos usar para la monitorización, tenemos decenas de buenas alternativas que podemos usar. Las hay más visuales, algunas están pensadas para entornos muy grandes, otras usan backends especializados (Cassandra por ejemplo), .... Queda a nuestra elección.
En lo que sí están de acuerdo la mayoría de aplicaciones es en la forma de detectar anomalías, sobre todo porque todas las que yo conozco se basan en este estupendo documento, que a la postre sirvió para la implementación en RRDTool. Siempre podéis diseñaros vuestro sistema, quizá usando R y su paquete forecast, pero esto está muy lejos del objetivo de este post.
En unos días describiré con más detalle una pequeña implementación de ejemplo sobre un servicio IMAP (Dovecot).