Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Websockets para administradores de sistemas Sat, 26 Feb 2011
Ya lo he escrito en el post anterior: Node.js es un proyecto muy interesante, muy adecuado como backend en muchos entornos, y particularmente en aquellos que dependen en gran medida del rendimiento I/O. Como ejemplo, aquí va uno de los últimos casos de éxito.
En este post, además de volver a usar Node.js y Redis (otro proyecto cada vez más importante), voy a dar cuatro pinceladas sobre una de las nuevas tendencias que van apareciendo en la web: WebSockets.
Para completar el ejercicio, escribiré un mini-proyecto para graficar todo tipo de valores numéricos en un plasmoid de KDE. Bueno, en realidad en cualquier navegador con soporte WebSockets (la lista es reducida, como veremos más adelante). Así, pasaremos a un punto de vista más de administrador de sistemas que de desarrollador web.
¿Qué son los WebSockets?
Internet es cada vez más "web". Las aplicaciones son cada vez más dinámicas, complejas e interactivas. Esto no es malo, obviamente, pero supone que mientras que los usuarios tienen más y más medios para interactuar con las webs, los administradores de estos entornos han visto como lo que antes se podía gestionar sin mayores problemas, ahora necesita todo tipo de caches e "inventos" sólo porque el sistema de votación de videos (por ejemplo) triplica la cantidad de accesos al sitio y a la base de datos.
Estos problemas no son, ni mucho menos, nuevos. Durante los últimos años se ha ido desarrollando mucha tecnología, para mejorar la experiencia de usuario, por supuesto, pero también para que la comunicación cliente/servidor sea más controlable y eficaz. Lo último: WebSockets.
Simplificando mucho, los WS básicamente ofrecen un canal full duplex entre el cliente y el servidor. De esta manera, en lugar de abrir una conexión web tradicional vía ajax (o similar) cada vez que se necesite un dato, el navegador crea un único canal permanente con el servidor, y lo usa tanto para enviar como para recibir datos. Esto último es importante, ya que el servidor puede usar la vía de comunicación activamente, por ejemplo para enviar un broadcast a todos sus clientes, y no sólo como respuesta ante una petición.
WS orientado a la administración de sistemas
Entonces, tenemos una nueva tecnología, muy orientada a la web, y por lo tanto muy fácil de usar. Además, ofrece algo que, aún sin ser tiempo real, es lo suficientemente ágil como para usarse para cosas como la monitorización de sistemas, que es precisamente el ejemplo con el que voy a seguir en este post.
Mi planteamiento inicial era hacer una pequeña aplicación que mostrase los datos de una base de datos rrd. Sin embargo, esto centraba el ejercicio demasiado en torno a la programación del módulo para Node.js, así que he preferido reutilizar los conceptos de otros posts anteriores, limitando el servidor WebSockets al envío de los datos que encuentre en una base de datos Redis.
Para hacerlo más interesante, el cliente será un plasmoid de KDE, aunque no deja de ser una página web normal y corriente, teniendo en cuenta que voy a usar el motor WebKit para su implementación (se pueden programar plasmoids en C, python, javascript, ...)
Las limitaciones
El protocolo WebSockets todavía es un draft del IETF. Ya sólo teniendo esto en cuenta podemos decir que está "verde".
En cuanto a navegadores, se necesita lo último de lo último en versiones (Opera, Firefox, Chrome, Safari...). Además, en el caso de Firefox (y Opera), el soporte, aunque presente, está deshabilitado por algunas lagunas en torno a la seguridad del protocolo cuando interactúa con un proxy. Ahora bien, para activarlo noy hay más que cambiar una clave (network.websocket.override-security-block).
Como ejemplo, para escribir este post he usado Ubuntu 10.10 y Fedora 14, con sus versiones respectivas de KDE, y con soporte para ejecutar plasmoids WebKit (cada distribución tiene su nombre de paquete, así que lo buscáis vosotros :-D ).
En la práctica, si queréis usar WebSockets en una aplicación "de verdad", hoy en día os recomiendo usar algo como socket.io, que es capaz de detectar lo que el navegador soporta, y en función de eso usar WS o simularlo con flash.
Bien, empecemos con la aplicación.
El servidor
Para guardar los datos vamos a usar Redis, con un hash que vamos a llamar "datos", y en el que guardaremos los valores a graficar. Traducido a perl:
my %datos;
$datos{todos} = 40;
$datos{server1} = 10;
$datos{server2} = 20;
$datos{server3} = 10;
Esto en Redis:
redis-cli hset datos todos 40 redis-cli hset datos server1 10 redis-cli hset datos server1 20 redis-cli hset datos server1 10
Para las pruebas he usado un bucle bash:
while true; do redis-cli hset datos todos $((10 + $RANDOM % 20)); sleep 1; done; ...
Existen varias formas de escribir un servidor WebSockets, pero pocas tan fácilies como Node.js y su módulo websocket-server. Tambien vamos a usar el módulo de Redis, así que:
npm install websocket-server npm install hiredis redis
Una vez instalados los componentes, es el momento de escribir las 70 líneas que hacen falta para tener un servidor 100% funcional y capaz de gestionar tantos gráficos como queramos:
var net = require('net');
var sys = require("sys");
var ws = require("websocket-server");
var redis = require("redis");
var puertoredis = 6379;
var hostredis = 'localhost';
var server = ws.createServer({debug: true});
var client = redis.createClient(puertoredis,hostredis);
var conexion;
var mensaje;
client.on("error", function (err) {
sys.log("Redis error en la conexion a: " + client.host + " en el puerto: " + client.port + " - " + err);
});
server.addListener("connection", function(conn){
var graficomostrado = "";
var servidores = [];
sys.log("Conexion abierta: " + conn.id);
client.hkeys("datos", function (err, replies) {
replies.forEach(function (reply, i) {
sys.log("Respuesta: " + reply);
servidores.push(reply);
});
graficomostrado = servidores[0];
mensaje = {"titulo": graficomostrado, "todos": servidores};
conn.send(JSON.stringify(mensaje));
});
conn.addListener("message", function(message){
var dato = JSON.parse(message);
if (dato) {
if (dato.orden == "changeGraphic") {
graficomostrado = dato.grafico;
conn.send(JSON.stringify({changedGraphic: graficomostrado}));
client.hget("datos", graficomostrado, function (err, reply) {
mensaje = {"inicio":[(new Date()).getTime(), reply]};
conn.send(JSON.stringify(mensaje));
});
} else if (dato.orden == "getData") {
client.hget("datos", graficomostrado, function (err, reply) {
mensaje = {"actualizacion":[(new Date()).getTime(), reply]};
conn.send(JSON.stringify(mensaje));
});
}
}
});
});
server.addListener("error", function(){
sys.log("Error de algun tipo en la conexion");
});
server.addListener("disconnected", function(conn){
sys.log("Desconectada la sesion " + conn.id);
});
server.listen(80);
Así de fácil es. Cuando un cliente establezca una conexión se llamará a:
server.addListener("connection", function(conn) {....
En este ejemplo, el trabajo fundamental de este bloque es enviar al cliente el listado de datos disponibles vía JSON:
....
mensaje = {"titulo": graficomostrado, "todos": servidores};
conn.send(JSON.stringify(mensaje));
A partir de aquí, la conexión está establecida. Cada vez que el cliente la use se llamará a:
conn.addListener("message", function(message) {....
En este caso, el servidor atenderá las peticiones de cambio de gráfico y de actualización de gráfico:
var dato = JSON.parse(message);
if (dato.orden == "changeGraphic") {
graficomostrado = dato.grafico;
conn.send(JSON.stringify({changedGraphic: graficomostrado}));
client.hget("datos", graficomostrado, function (err, reply) {
mensaje = {"inicio":[(new Date()).getTime(), reply]};
conn.send(JSON.stringify(mensaje));
});
} else if (dato.orden == "getData") {
client.hget("datos", graficomostrado, function (err, reply) {
mensaje = {"actualizacion":[(new Date()).getTime(), reply]};
conn.send(JSON.stringify(mensaje));
});
}
Y con hacer que el servidor escuche en el puerto 80... ¡A correr!
server.listen(80);
El cliente
El código del servidor y del cliente está disponible en Github, así que voy a limitar la explicación a lo fundamental, dejando a un lado el uso de Jquery, Jquery-ui o de la excelente librería Highcharts, que he usado a pesar de no ser completamente libre, porque me ha permitido terminar el ejemplo mucho más rápido.
Una aplicación que quiere usar WebSockets debe comprobar si el navegador lo permite:
if (!("WebSocket" in window)) {
// No tiene soporte websockets, deshabilitamos botones.
$('#containergraficos').empty();
$('#containergraficos').html('Sin soporte WebSockets.
');
$("#conectar").button({ disabled: true });
} else {
// Sí tiene soporte websockets
socket = new WebSocket(host);
}
A partir de aquí, sólo queda reaccionar ante cada evento:
socket.onopen = function(){
.......
}
socket.onmessage = function(msg){
// código íntegro en github
var resultado = JSON.parse(msg.data);
if (resultado.inicio) {
var datos = [];
datos.push({x: parseInt(resultado.inicio[0]), y: parseInt(resultado.inicio[1])});
options.series[0].data = datos;
chart = new Highcharts.Chart(options);
} else if (resultado.actualizacion) {
chart.series[0].addPoint({x: parseInt(resultado.actualizacion[0]), y: parseInt(resultado.actualizacion[1])});
} else if (resultado.changedGraphic) {
$("#grafico").button("option", "label", resultado.changedGraphic);
} else if (resultado.titulo) {
$("#grafico").button("option", "label", resultado.titulo);
var mensaje = {"orden": "changeGraphic", "grafico": resultado.titulo};
socket.send(JSON.stringify(mensaje));
}
}
socket.onclose = function(){
...
}
socket.onerror = function() {
...
}
En definitiva, unos pocos mensajes JSON de un lado para otro del socket.
Además, cada 5 segundos vamos a hacer que Highcharts pida datos nuevos:
events: {
load: function() {
var series = this.series[0];
setInterval(function() {
if (socket) {
var mensaje = {"orden": "getData", "grafico": grafico};
socket.send(JSON.stringify(mensaje));
} else {
var x = (new Date()).getTime();
series.addPoint([x, 0], true, true);
}
}, 5000); //5 segundos
}
}
El plasmoid
Evidentemente, hasta ahora no hemos hecho nada que no se pueda ejecutar en un navegador. Ahora lo empaquetaremos en un plasmoid, aunque no deja de ser más que un zip con todo el contenido y un fichero metadata.desktop con la descripción del propio plasmoid, que entre otros inlcuye:
[Desktop Entry] Name=Forondarenanet Comment=Pruebas para forondarena.net Icon=chronometer Type=Service X-KDE-ServiceTypes=Plasma/Applet X-Plasma-API=webkit X-Plasma-MainScript=code/index.html X-Plasma-DefaultSize=600,530
KDE tiene una utilidad para probar los plasmoids sin instalarlos, llamada "plasmoidviewer". Una vez probado, se puede instalar con:
plasmapkg -i forondarenanet.plasmoid
Recordad que el fichero no es más que un zip. En este caso, la estructura es la siguiente:
./metadata.desktop ./contents ./contents/code ./contents/code/css ./contents/code/css/images ./contents/code/css/images/ui-bg_gloss-wave_16_121212_500x100.png ... ./contents/code/css/images/ui-icons_cd0a0a_256x240.png ./contents/code/css/jquery-ui-1.8.9.custom.css ./contents/code/css/forondarenanet.css ./contents/code/index.html ./contents/code/js ./contents/code/js/jquery-1.4.4.min.js ./contents/code/js/highcharts.js ./contents/code/js/forondarenanet.js ./contents/code/js/jquery-ui-1.8.9.custom.min.js ./contents/code/img
Y poco más. Para terminar con un ejemplo, cuatro plasmoids mostrando gráficos diferentes:
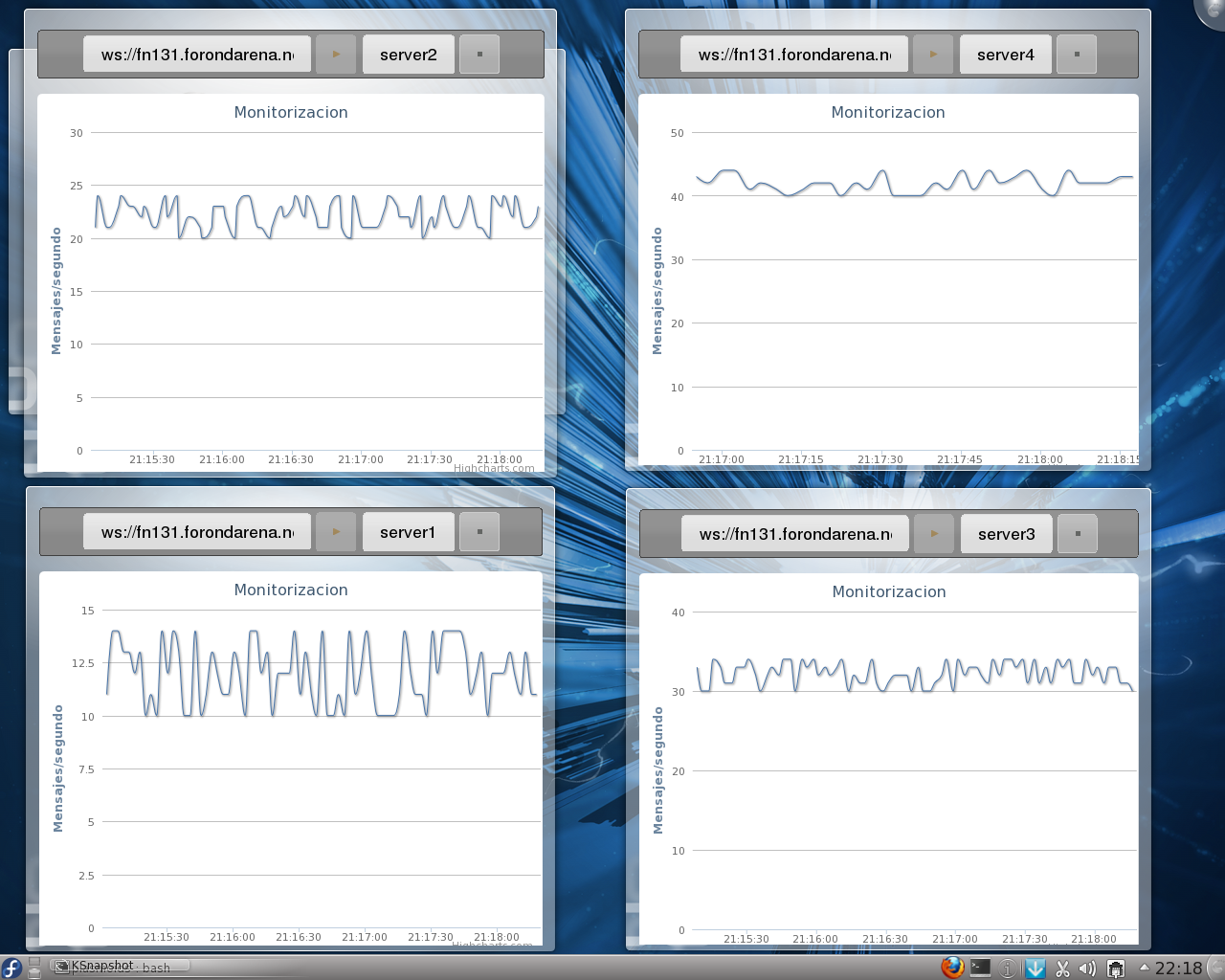
Que por supuesto, sólo generan 4 conexiones, a pesar de estar actualizándose cada 5 segundos:
# netstat -nt Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 192.168.10.136:36903 192.168.10.131:80 ESTABLISHED tcp 0 0 192.168.10.136:36904 192.168.10.131:80 ESTABLISHED tcp 0 0 192.168.10.136:36905 192.168.10.131:80 ESTABLISHED tcp 0 0 192.168.10.136:36906 192.168.10.131:80 ESTABLISHED