Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Computación distribuida con Hadoop II Fri, 05 Feb 2010
Continúo la serie de posts sobre Hadoop describiendo, muy por encima, los componentes y la estructura que suelen tener este tipo de sistemas. Como ya he dicho en otros posts, este blog pretende ser sobre todo práctico, así que no me voy a extender demasiado.
Gráficamente un cluster Hadoop se puede parecer mucho a esto:
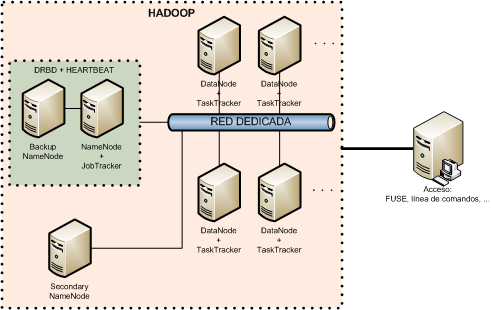
JobTracker:
En un cluster hay un único JobTracker. Su labor principal es la gestión de los TaskTrackers, entre los que distribuye los trabajos MapReduce que recibe. Es, por lo tanto, el interfaz principal que tienen los usuarios para acceder al cluster.
TaskTracker:
Un cluster tiene n TaskTrackers que se encargan de la ejecución de las tareas map y reduce en los nodos. Cada uno de los TaskTrackers gestiona la ejecución de estas tareas en una máquina del cluster. El JobTracker se encarga, a su vez, de controlarlos.
NameNode:
Las funciones principales del NameNode son el almacenamiento y la gestión de los metadatos del sistema de ficheros distribuido y ofrecer el interfaz principal que tiene el usuario para acceder al contenido HDFS. En un cluster hay un único proceso NameNode.
Sin los metadatos que mantiene el NameNode no se sabría en qué nodo está cada bloque, además de perderse la información sobre la estructura de directorios. Es, por lo tanto, el componente más importante del cluster, y debe estar redundado. Hadoop no ofrece de manera nativa ningún mecanismo de alta disponibilidad, pero sí dispone de herramientas que permiten replicar la información. Entre ellas está el NameNode secundario, que permite guardar una copia de los metadatos (en realidad hace más cosas) en una máquina diferente al NameNode. Eso sí, no es una copia en tiempo real, y no ofrece failover automático en caso de fallo del primario. Para esto necesitamos usar otro tipo de herramientas, entre las que destacan DRBD y Heartbeat.
DataNode:
Estos procesos ofrecen el servicio de almacenamiento de bloques para el sistema de ficheros distribuido. Son coordinados por el NameNode.
Estos son los procesos principales del sistema, pero hay otros, como el Balancer, que se encarga de equilibrar la distribución de los bloques entre los DataNodes, por ejemplo cuando se añade un nuevo servidor.
Mi laboratorio se limita a cuatro servidores: un NameNode+JobTracker y tres DataNode+TaskTracker, en cuatro máquinas virtuales de un core y 1G de memoria, para un total de 5G de almacenamiento.
hadoop@fn140:/usr/local/hadoop/conf$ hadoop dfsadmin -report Configured Capacity: 8695013376 (8.1 GB) Present Capacity: 5455364096 (5.08 GB) DFS Remaining: 5455290368 (5.08 GB) DFS Used: 73728 (72 KB) DFS Used%: 0% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 3 (3 total, 0 dead) Name: 192.168.10.142:50010 Decommission Status : Normal Configured Capacity: 2898337792 (2.7 GB) DFS Used: 24576 (24 KB) Non DFS Used: 1079918592 (1.01 GB) DFS Remaining: 1818394624(1.69 GB) DFS Used%: 0% DFS Remaining%: 62.74% Last contact: Sun Jan 31 16:10:58 CET 2010 Name: 192.168.10.143:50010 Decommission Status : Normal Configured Capacity: 2898337792 (2.7 GB) DFS Used: 24576 (24 KB) Non DFS Used: 1080020992 (1.01 GB) DFS Remaining: 1818292224(1.69 GB) DFS Used%: 0% DFS Remaining%: 62.74% Last contact: Sun Jan 31 16:10:58 CET 2010 Name: 192.168.10.141:50010 Decommission Status : Normal Configured Capacity: 2898337792 (2.7 GB) DFS Used: 24576 (24 KB) Non DFS Used: 1079709696 (1.01 GB) DFS Remaining: 1818603520(1.69 GB) DFS Used%: 0% DFS Remaining%: 62.75% Last contact: Sun Jan 31 16:10:56 CET 2010
En los próximos dos posts voy a dejar la "teoría" para pasar a la práctica, empezando por una de las aplicaciones más obvias de Hadoop, como es el tratamiento de logs; para seguir por una de las utilidades que existen para facilitar el desarrollo de aplicaciones MapReduce: pig.