Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Instalaciones automáticas desde usb Sun, 14 Jul 2013
Vamos a suponer por un momento que estamos en un entorno en el que no podemos tener un servidor PXE en condiciones. Para ponerlo todavía peor, imaginemos que somos de los que no conseguimos encontrar un cd de Knoppix razonablemente reciente cada vez que se nos fastidia un servidor y que, a pesar de las prisas, tenemos que esperar a ver como carga todo un entorno gráfico antes de poder hacer un simple fsck.
Todo esto tendría que ser parte del pasado, al estilo de los videos Beta o los cassettes; pero no, todavía es demasiado común, así que a ver si conseguimos dar algunas ideas útiles y buscamos alternativas que, aunque no sean lo más moderno que existe, nos faciliten un poco el trabajo.
No esperéis nada original en este post. Todo lo que escribo aquí está ya más que documentado, y mucho mejor que en estas cuatro notas. Aún así, a ver si os sirve como punto de partida.
Queremos conseguir dos cosa:
- Un método para arrancar rápidamente una distribución live, sencilla, que permita recuperar particiones, transferir ficheros, ..., este tipo de cosas.
- Un sistema para instalar distribuciones de forma automática, usando ficheros kickstart para RedHat/CentOS/... y preseed para Debian/Ubuntu/..., pero teniendo en cuenta que no podemos usar PXE, ni Cobbler, ni nada similar.
Ya hace mucho tiempo que se pueden arrancar sistemas desde memorias USB, y además GRUB tiene funcionalidades que permiten arrancar desde una ISO. Siendo esto así, ya tenemos todo lo necesario. Si incluimos un servidor web para guardar nuestros ficheros ks y preseed y, si queremos acelerar un poco las instalaciones, los paquetes de las distribuciones CentOS y Debian (las que voy a usar en este post), conseguiremos además que las instalaciones sean automáticas y razonablemente dinámicas.
Pasos previos
Empezamos. Buscad un pendrive que no uséis para nada y podáis formatear. Desde este momento asumo que el dispositivo que estáis usando corresponde a /dev/sde, y que tiene una única partición fat normal y corriente, en /dev/sde1. Si no es así, lo de siempre: "fdisk /dev/sde" + "mkfs.vfat -n USB_INSTALACIONES /dev/sde1":
#fdisk -l /dev/sde Disposit. Inicio Comienzo Fin Bloques Id Sistema /dev/sde1 * 2048 15654847 7826400 c W95 FAT32 (LBA)
Una vez más, aseguráos de que podéis y queréis borrar el contenido del pendrive. Por supuesto, vuestro kernel debe tener soporte para este tipo de particiones, y también necesitáis las utilidades para gestionarlas. En Debian están en el paquete "dosfstools". En cualquier caso, lo normal es que ya lo tengáis todo.
Vamos a montar la partición en "mnt" (o donde queráis), con un simple:
mount /dev/sde1 /mnt
Lo siguiente es instalar grub en /dev/sde. Otra vez, cuidado con lo que hacéis, no os confudáis de dispositivo.
grub-install --no-floppy --root-directory=/mnt /dev/sde
Dejamos estos pasos básicos y vamos ya a por la configuración más específica.
Creando el menú
En realidad, no vamos a hacer nada más que configurar GRUB. Podéis ser todo lo creativos que queráis, pero para este ejemplo voy a simplificar todo lo que pueda: Ni colores, ni imágenes de fondo, ni nada de nada.
Para tener un poco de variedad, desde mi USB se va a poder arrancar lo siguiente:
- Una Debian Wheezy sin preseed, para ir configurando a mano.
- Un CD con utilidades de repación. El que más os guste. Para este ejemplo: Ultimate BootCD.
- Una Slax, por si quisiera arrancar un entorno gráfico completo.
- Una Debian Wheezy con preseed, completamente automática.
- Una CentOS 6.4 con kickstart, completamente automática.
Prestad atención a los dos últimos elementos de la lista, porque son los que nos van a permitir ir a un servidor "vacío", arrancar desde el USB, y en 5 minutos tener una Debian o una CentOS perfectamente instalados.
Vamos a crear el menú de GRUB. Necesitamos editar el fichero "/mnt/boot/grub/grub.cfg" con lo siguiente:
menuentry "Debian Wheezy x86_64 installer" {
set gfxpayload=800x600
set isofile="/boot/iso/wheezy_mini_amd64.iso"
loopback loop $isofile
linux (loop)/linux priority=low initrd=/initrd.gz
initrd (loop)/initrd.gz
}
menuentry "Ultimate BootCD 5.2.5" {
loopback loop /boot/iso/ubcd525.iso
linux (loop)/pmagic/bzImage edd=off load_ramdisk=1 prompt_ramdisk=0 rw loglevel=9 max_loop=256 vmalloc=384MiB keymap=es es_ES iso_filename=/boot/iso/ubcd525.iso --
initrd (loop)/pmagic/initrd.img
}
menuentry "Slax Spanish 7.0.8 x86_64" {
set isofile="/boot/iso/slax-Spanish-7.0.8-x86_64.iso"
loopback loop $isofile
linux (loop)/slax/boot/vmlinuz load_ramdisk=1 prompt_ramdisk=0 rw printk.time=0 slax.flags=toram from=$isofile
initrd (loop)/slax/boot/initrfs.img
}
menuentry "Debian Wheezy x86_64 preseed" {
set isofile="/boot/iso/wheezy_mini_amd64.iso"
loopback loop $isofile
linux (loop)/linux auto=true preseed/url=http://192.168.10.40/instalaciones/wheezy_preseed_131.cfg debian-installer/country=ES debian-installer/language=es debian-installer/keymap=es debian-installer/locale=es_ES.UTF-8 keyboard-configuration/xkb-keymap=es console-keymaps-at/keymap=es debconf/priority=critical netcfg/disable_dhcp=true netcfg/get_ipaddress=192.168.10.131 netcfg/get_netmask=255.255.255.0 netcfg/get_gateway=192.168.10.1 netcfg/get_nameservers=192.168.10.1 --
initrd (loop)/initrd.gz
}
menuentry "Centos 6.4 x86_64 kickstart" {
set isofile="/boot/iso/CentOS-6.4-x86_64-netinstall.iso"
loopback loop $isofile
linux (loop)/images/pxeboot/vmlinuz ip=192.168.10.131 noipv6 netmask=255.255.255.0 gateway=192.168.10.1 dns=192.168.10.1 hostname=fn131.forondarena.net ks=http://192.168.10.40/instalaciones/ks_rh6_131.ks lang=es_ES keymap=es
initrd (loop)/images/pxeboot/initrd.img
}
menuentry "Restart" {
reboot
}
menuentry "Shut Down" {
halt
}
Suficiente, no necesitamos nada más. Repasemos un poco:
- Las entradas del menú se separan en bloques "menuentry", uno para cada instalación diferente, e incluyendo las dos últimas para reiniciar y para apagar el equipo (no son muy útiles pero sirven de ejemplo).
- Como no me gusta escribir demasiado, he definido la variable, "isofile" con la imagen que va a usar GRUB para arrancar (ahora hablamos sobre esto) en cada bloque.
- Vamos a usar imágenes ISO "normales", y GRUB va a asumir que son la raíz de la instalación.
- Como sabéis, cuando queremos arrancar un sistema, es habitual especificar un kernel en una línea que empieza con "linux", las opciones que queremos usar con este núcleo, y un initrd. Aquí estamos haciendo exactamente esto, pero debemos especificar la ruta dentro de la imagen ISO donde encontrar el kernel y el initrd. Lo más fácil es que montéis la imagen y veáis dónde está cada uno.
- Las dos instalaciones automáticas usan más opciones que el resto. Lo que estamos haciendo es pasar el fichero de configuración (preseed o kickstart) que el sistema leerá vía http, y luego una serie de opciones básicas (idioma, teclado, ...). Ni todas son necesarias, ni son todas las que se pueden poner.
- Como hemos dicho que no queremos usar PXE, asumo que tampoco queremos usar DHCP, así que las configuraciones de red son estáticas.
- La IP que asignamos al servidor en esta fase de instalación no tiene que ser necesariamente la misma que instalaremos en el servidor, aunque en este ejemplo asumo que será así.
Fácil, ¿Verdad? El siguiente paso es descargar las imágenes que estamos usando en cada bloque (opción "isofile"). Tened en cuenta que no hay nada raro en estas ISO. Son las imágenes estándar de las distribuciones, aunque las he renombrado para que todo quede más ordenado. Para guardarlas he creado un directorio "/mnt/boot/iso/", y he copiado ahí los siguientes ficheros:
- Para Debian, con y sin preseed: mini.iso (renombrada a wheezy_mini_amd64.iso).
- Para CentOS: netinstall.iso.
- Para Ultimate BootCD: ubcd.
- Para Slax: slax.
Cuando lo tengáis todo, desmontad /mnt, y ya habremos terminado con el pendrive. Quedan los preseed/kickstart.
Ficheros kickstart y preseed
Si os fijáis en el menú de GRUB, para Debian estamos usando una referencia al fichero wheezy_preseed_131.cfg. Este fichero no es más que un preseed normal y corriente que, obviamente, está preparado para la instalación que queremos hacer. Los ficheros preseed consisten en escribir todas las respuestas a todas las opciones de menú que pueden aparecer en el instalador. Esto hace que el sistema sea muy flexible, pero también muy denso. Si queréis ver un listado con todas las opciones disponibles, id a una máquina Debian y ejecutad lo siguiente:
debconf-get-selections --installer >> wheezy_preseed_131.cfg debconf-get-selections >> wheezy_preseed_131.cfg
Ahí tenéis, todo un "wheezy_preseed_131.cfg"; una locura. Afortunadamente, no siempre hacen falta todas las opciones. De hecho, yo en mis instalaciones para KVM uso esta versión, mucho más reducida. Claro, esto implica que si os sale un diálogo durante la instalación para el que no hemos previsto una respuesta, quizá porque vuestro hardware pida "algo" extra, la instalación automática se va a parar. En este caso tendréis que buscar la opción que os falta y añadirla.
Os recomiendo que abráis el fichero y que le déis una vuelta. Tened en cuenta que está pensado para instalaciones sobre KVM y los drivers virtio, así que el dispositivo de disco que se usa es /dev/vda. Además, uso sólo un interfaz de red, eth0. En cuanto al particionado, uso una partición para boot, primaria y de 50MB, otra para swap de unos 512MB, y por último, el resto del disco, en un grupo LVM para la raíz.
Además de esto, suelo usar un mirror local de Debian para agilizar la primera instalación. No es necesario, podéis usar un mirror público y, con ello, simplificar aún más la infraestructura. Bueno, "simplificar" por decir algo, porque no se puede decir que copiar el contenido de los DVD de instalación de Debian en un servidor web sea complicado.
Aunque el sistema sea diferente, en realidad todo esto que he dicho para Debian se aplica igual para kickstart y las instalaciones automatizadas de CentOS. Revisad si queréis este ejemplo, subidlo a un servidor web, y adaptadlo a lo que os haga falta. Tened en cuenta que también suelo usar un mirror local en estos casos (otra vez, se trata sencillamente de descomprimir los DVD).
Pruebas en KVM
Una vez instalado GRUB, con el menú y las ISO copiadas en el pendrive, podemos probar el nuevo sistema en KVM. Es muy sencillo. De hecho, si usáis virt-manager, casi no tendréis que hacer nada. Una vez creada la máquina virtual, id a los detalles y pulsad sobre "agregar nuevo hardware". Después no tenéis más que elegir "usb host device" y, de la lista, la memoria USB. Una vez agregado el dispositivo, en el arranque de la máquina virtual, justo al principio, aparecerá una opción para acceder al menú de arranque pulsando F12. Entre las opciones que os van a aparecer debería estar el pendrive.
Por último, esto es lo que veréis si todo ha ido bien:
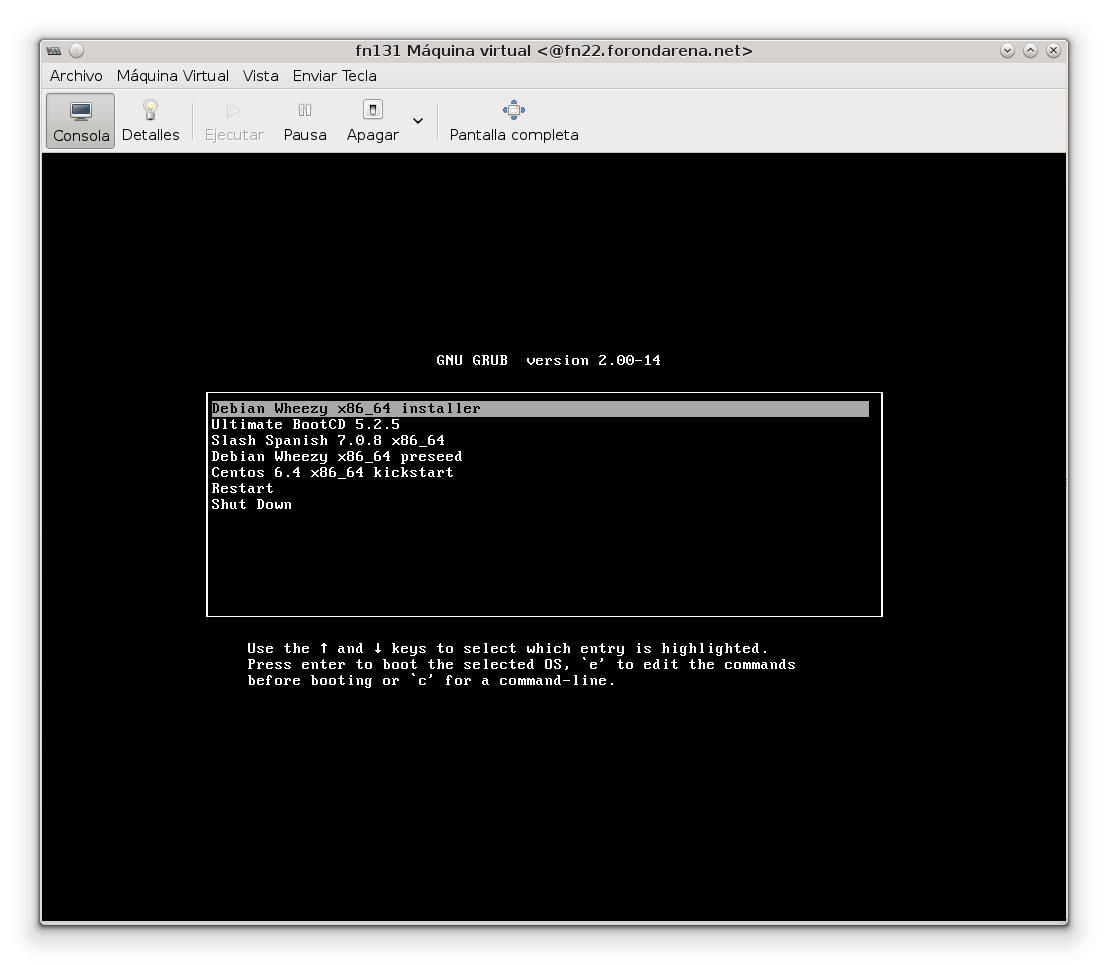
Y ya está, con esto hemos terminado. Romped vuestros CDs!!
Nota
En el post hablo sobre un servidor web, pero luego no escribo nada más sobre ello. No hay demasiado que decir; en mi caso uso un directorio "instalaciones", y en ese directorio pongo los preseed/ks. Junto a esto, debajo de "instalaciones", creo un directorio "centos/6.4-x86_64" y otro "debian/wheezy" y copio ahí el contenido de los DVD de cada distribución.
Enrutamiento para dummies Thu, 27 Sep 2012
Si hay algo sobre lo que no hubiese querido escribir nunca en este blog es sobre el enrutamiento básico en Linux. Hace 10 años quizá hubiese sido más interesante, pero no ahora. Aún así, en este mundo del botón y del siguiente siguiente no tengo nada claro que la gente …
Leer másrsyslog y zeroMQ Sun, 06 Nov 2011
Con la evolución de los sistemas actuales, cada vez más grandes, con más elementos interconectados, con más necesidades de comunicación; con el cloud computing, las nubes, nieblas y demás parafernalia, llevamos ya tiempo viendo como las diferentes implementaciones de Advanced Message Queuing Protocol, como RabbitMQ, van ganando más y más …
Leer másPXE para instalaciones básicas de CentOS y Debian Thu, 20 Oct 2011
Otro mini-post que vuelve a salirse completamente de la idea general de este blog. Ya hay mucha documentación sobre PXE y sobre instalaciones automatizadas tanto de CentOS como de Debian, pero bueno, a ver si le es útil a alguien.
En este caso, vamos a montar un sencillo servidor PXE …
Leer másBuzones compartidos con Dovecot Sun, 02 Oct 2011
Ahora que ando reestructurando mi laboratorio, voy a aprovechar para documentar un par de aplicaciones que estoy moviendo al nuevo hierro.
En realidad, esto se sale un poco del objetivo de este blog, sobre todo teniendo en cuenta que ya hay kilos de documentación sobre, en este caso, Dovecot; pero …
Leer más