Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Monitorización del kernel con SystemTap II Sat, 11 Apr 2009
A veces (seguro que pocas), nos encontramos ante una máquina que por algún motivo ha dejado de trabajar como se esperaba. Digamos que el rendimiento o el IO del equipo baja, sin motivo visible. Digamos que no hay logs que indiquen problemas, ni errores del sistema. Nada. Este es el momento para el kung fu, el voodoo o todo tipo de técnicas adivinatorias que tanto usamos los informáticos. Muchas veces es suficiente, pero no siempre, y no hay nada peor que no ser capaz de dar una explicación a un problema.
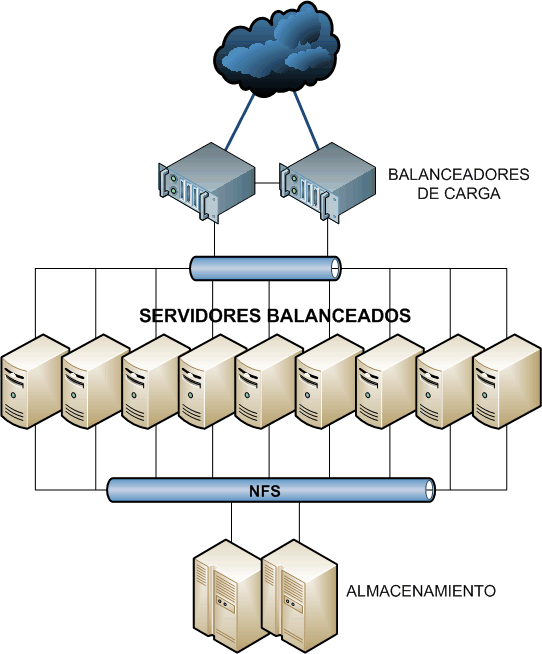
Supongamos que tenemos la arquitectura de la imagen, con un par de balanceadores de carga, unas cuantas máquinas iguales que pueden ser servidores web, ftp, pop, smtp o cualquier otra cosa, y un par de servidores de almacenamiento nfs. Teniendo en cuenta que los balanceadores de carga suelen dar la posibilidad de asignar diferentes pesos a cada máquina balanceada, ¿Por qué no usar uno de estos servidores para la monitorización del sistema? Es perfectamente posible enviar un poco menos de tráfico a la máquina destinada a SystemTap, de tal manera que no afecte al rendimiento global, para que podamos darnos un mecanismo para tener nuestra infraestructura controlada.
En este post sólo voy a referenciar algunos scripts que están disponibles en la web y en el redpaper. Además, el propio software viene con muchos ejemplos. En CentOS se puede instalar el rpm "systemtap-testsuite" para probar varios scripts.
Vamos a empezar con un par de ejemplos para usar más en un entorno académico que en la práctica.
Digamos que queremos aprender "lo que pasa" cuando hacemos un "ls" en un directorio de una partición ext3. Con este sencillo script:
#! /usr/bin/env stap
probe module("ext3").function("*").call
{
printf("%s -> %s\n", thread_indent(1), probefunc())
}
probe module("ext3").function("*").return
{
printf("%s <- %s\n", thread_indent(-1), probefunc())
}
Vamos a hacer un printf cada vez que comience y termine la ejecución de cualquier función del módulo ext3. En el printf vamos a tabular el nombre de la función que se ha ejecutado. El resultado es algo así:
... 2 ls(31789): <- ext3_permission 0 ls(31789): -> ext3_dirty_inode 8 ls(31789): -> ext3_journal_start_sb 21 ls(31789): <- ext3_journal_start_sb 26 ls(31789): -> ext3_mark_inode_dirty 31 ls(31789): -> ext3_reserve_inode_write 35 ls(31789): -> ext3_get_inode_loc 39 ls(31789): -> __ext3_get_inode_loc 52 ls(31789): <- __ext3_get_inode_loc 56 ls(31789): <- ext3_get_inode_loc 61 ls(31789): <- ext3_reserve_inode_write 67 ls(31789): -> ext3_mark_iloc_dirty 74 ls(31789): <- ext3_mark_iloc_dirty 77 ls(31789): <- ext3_mark_inode_dirty 83 ls(31789): -> __ext3_journal_stop 87 ls(31789): <- __ext3_journal_stop 90 ls(31789): <- ext3_dirty_inode 0 ls(31789): -> ext3_permission ...
Como he dicho, no es algo demasiado práctico, pero puede servir a algún profesor para suspender a un buen porcentaje de pobres alumnos :-) Sigamos con algún otro ejemplo. Digamos que queremos programar un "nettop" que nos diga qué conexiones se están abriendo en una máquina en cada momento. Con un script similar al siguiente lo tendremos en unos minutos:
#! /usr/bin/env stap
global ifxmit, ifrecv
probe netdev.transmit
{
ifxmit[pid(), dev_name, execname(), uid()] <<< length
}
probe netdev.receive
{
ifrecv[pid(), dev_name, execname(), uid()] <<< length
}
function print_activity()
{
printf("%5s %5s %-7s %7s %7s %7s %7s %-15s\n",
"PID", "UID", "DEV", "XMIT_PK", "RECV_PK",
"XMIT_KB", "RECV_KB", "COMMAND")
foreach ([pid, dev, exec, uid] in ifrecv-) {
n_xmit = @count(ifxmit[pid, dev, exec, uid])
n_recv = @count(ifrecv[pid, dev, exec, uid])
printf("%5d %5d %-7s %7d %7d %7d %7d %-15s\n",
pid, uid, dev, n_xmit, n_recv,
n_xmit ? @sum(ifxmit[pid, dev, exec, uid])/1024 : 0,
n_recv ? @sum(ifrecv[pid, dev, exec, uid])/1024 : 0,
exec)
}
print("\n")
delete ifxmit
delete ifrecv
}
probe timer.ms(5000), end, error
{
print_activity()
}
¿Qué es lo que hemos hecho? Hemos generado tres "probes". Por un lado, cuando se recibe o trasmite a través de la red añadimos a los arrays "ifxmit, ifrecv" información sobre qué proceso y en qué interfaz ha enviado o recibido. Por otro lado, cada 5000 ms o cuando haya un error o termine el script mostramos la información por pantalla. El resultado puede ser algo similar a lo siguiente:
PID UID DEV XMIT_PK RECV_PK XMIT_KB RECV_KB COMMAND 31485 500 eth0 1 1 0 0 sshd y pasados unos miles de milisegundos ... PID UID DEV XMIT_PK RECV_PK XMIT_KB RECV_KB COMMAND 15337 48 eth0 4 5 5 0 httpd 31485 500 eth0 1 1 0 0 sshd
Como se ve, tengo una sesión ssh abierta permanentemente, y he consultado una página web en el servidor monitorizado. Por supuesto, esto puede no ser muy práctico en servidores muy activos, pero puede dar alguna idea a algún administrador. Igual que hemos hecho un "nettop", también podemos hacer un "disktop" que muestre un resultado como el siguiente:
Sat Apr 11 17:22:03 2009 , Average: 0Kb/sec, Read: 0Kb, Write: 0Kb
UID PID PPID CMD DEVICE T BYTES
48 15342 15239 httpd dm-0 W 210
48 15343 15239 httpd dm-0 W 210
48 15337 15239 httpd dm-0 W 210
48 15336 15239 httpd dm-0 W 210
Lo que hecho es hacer el mismo wget varias veces. Para el que tenga curiosidad, los procesos httpd (que por cierto usa el usuario id=48) ejecutando en el servidor son:
# pstree -p | grep http
|-httpd(15239)-+-httpd(15336)
| |-httpd(15337)
| |-httpd(15338)
| |-httpd(15339)
| |-httpd(15340)
| |-httpd(15341)
| |-httpd(15342)
| `-httpd(15343)
El script disktop está disponible en "/usr/share/systemtap/testsuite/systemtap.examples/io" del rpm "systemtap-testsuite".
Volvamos al primer ejemplo del post. Teníamos un grupo de servidores que han dejado de funcionar como deben. Digamos que sospechamos de la velocidad con la que nuestros servidores nfs están sirviendo el contenido de los servidores web. Podemos probar aquellos ficheros que necesiten más de 1 segundo para abrirse:
#!/usr/bin/stap
global open , names
probe begin {
printf("%10s %12s %30s\n","Process" , "Open time(s)" , "File Name")
}
probe kernel.function("sys_open").return{
open[execname(),task_tid(task_current()),$return] = gettimeofday_us()
names[execname(),task_tid(task_current()),$return] = user_string($filename)
}
probe kernel.function("sys_close"){
open_time_ms = (gettimeofday_us() - open[execname(),task_tid(task_current()), $fd])
open_time_s = open_time_ms / 1000000
if ((open_time_s >= 1) && (names[execname(),task_tid(task_current()), $fd] != "")) {
printf("%10s %6d.%.5d %30s\n", execname(),
open_time_s,open_time_ms%1000000,names[execname(),task_tid(task_current()), $fd])
}
}
Con este sencillo script estaría hecho:
Process Open time(s) File Name
httpd 8.471285 /var/www/html/lectura_lenta.html
En este caso al servidor web le ha costado 8.5 segundos servir el fichero lectura_lenta.html. Después será responsabilidad nuestra buscar, en su caso, la solución.
En definitiva, systemtap es una herramienta muy completa, pero que como tal requiere algo de práctica para ser útil. No sé si alguna vez va a tener mucho éxito en entornos de producción, pero no está de más saber que existe.