Feeds 3
Artículos recientes
Nube de tags
seguridad
mfa
dns
zerotrust
monitorizacion
kernel
bpf
sysdig
port knocking
iptables
linux
pxe
documentación
rsyslog
zeromq
correo
dovecot
cassandra
solandra
solr
systemtap
nodejs
redis
hadoop
mapreduce
firewall
ossec
psad
tcpdump
tcpflow
Categorías
Archivo
Proyectos
Documentos
Blogs
Servidor pop-before-smtp en 67 líneas con nodejs y redis Wed, 01 Dec 2010
Llevaba tiempo, la verdad, queriendo escribir un post sobre una de esas nuevas herramientas que aparecen de vez en cuando, que prometen un montón de cosas, pero que en realidad nunca sabemos hasta dónde van a llegar. En este caso me estoy refiriendo a node.js.
Buscando algo que programar se me ha ocurrido escribir un sencillo servidor popbeforesmtp con node.js. La verdad es que resulta algo paradógico usar algo tan nuevo para esto, cuando pbs (vamos abreviando) es uno de los sistemas de autentificación más odiados del mundo del correo electrónico, propio de una época en la que el spam casi ni existía (buff!!). Como decía, no es más que una excusa para hacer algo "práctico" con node.js.
Los tres lectores de mi blog saben lo que es pbs, pero probablemente no hayan oido hablar sobre node.js. A ver si sacamos algo en claro de todo esto.
El problema
Digamos que tenemos un sistema con unos cuantos servidores SMTP que usamos para enviar correo. Aunque normalmente usamos algún tipo de validación ESMTP, tenemos que mantener la compatibilidad con algunos clientes de correo que han venido enviando correo sin ningún problema sólo a través de validación POP.
Pop before smtp permite que un cliente de correo pueda enviar un mensaje una vez se haya validado vía POP. El servidor SMTP, por lo tanto, debe ser capaz de guardar un histórico de conexiones y de permitir envíos, normalmente durante unos pocos minutos, sin pedir ningún otro tipo de credencial.
Ya tenemos todos los elementos que necesitamos sobre la mesa. Veamos:
- Un servidor SMTP sobre el que implementar "el invento".
- Un servidor POP desde el que obtener la información de validación.
- Una aplicación que relacione ambos mundos, y que sea capaz de funcionar tanto en una infraestructura de una máquina como en clusters de varios servidores POP y SMTP (con todo lo que esto significa).
Un servidor SMTP
Actualmente tenemos en el mercado open source cuatro tres servidores SMTP que podemos usar:
- Postfix
- Exim
- Sendmail
- Qmail
Cada uno usa sus propios mecanismos de auntentificación. Para este ejemplo me voy a centrar en Postfix.
Postfix tiene muchos controles "nativos" para permitir o denegar envíos de correo. Se pueden establecer políticas de acceso en base a IPs origen, cuentas origen, destino, helo, contenido, .... De hecho, también se pueden escribir reglas compuestas que combinen las anteriores.
Sin embargo, para pbs necesitamos mantener un listado de IPs para las que se permiten envíos(fácil), pero que expiren cada x minutos.
Para estos casos más elaborados Postfix ofrece lo que se llama access policy delegation, y que no es más que un sencillo API para conectarse con una aplicación externa que se encargará de tomar las decisiones de validación.
Dicho de otra forma, Postfix enviará a un socket (UNIX o TCP) la información de la sesión SMTP que se quiere comprobar, y recibirá por ese mismo socket el "OK" (o no) correspondiente.
El software que vamos a escribir, por lo tanto, va a recibir esto por un socket:
request=smtpd_access_policy protocol_state=RCPT protocol_name=ESMTP client_address=192.168.10.131 client_name=fn131.example.org reverse_client_name=fn131.example.org helo_name=example.org sender=patata@example.org recipient=nospam@example.com ......
A lo que tiene que responder generalmente o "OK", o "reject", o "dunno". [1]
Un servidor POP
El que más nos guste (Dovecot, Courier, ...). El único requerimiento es que escriba en un log parseable los login de usuarios.
Una aplicación encargada de la política
Aquí está lo interesante de este post. Veamos lo que necesitamos:
- Una aplicación, en nuestro caso un servidor TCP, que reciba las conexiones desde Postfix y entregue las respuestas.
- Una base de datos de algún tipo que almacene la información. A ser posible, debe poder distribuirse entre muchos servidores SMTP de forma transparente.
- Un procesador de logs POP capaz de insertar registros en la base de datos que usará la aplicación.
Empecemos por la base de datos. Estamos hablando básicamente de "algo" sencillo, en lo que guardar un listado de IPs, y que además auto-expire los registros pasados unos minutos. Además, debe ser lo más rápida posible y permitir un gran número de conexiones simultáneas.
Vaya, si estamos hablando de....Memcached.
Pros:
- Estable. Muchos años en entornos muy importantes.
- Perfecta para guardar claves (IPs) y valores (cualquier cosa en este caso. El rcpt nos podría venir bien).
- Expira automáticamente los registros antiguos.
- Tiene interfaces perl, python, ....
- Rápida.
Cons:
- ¿Cómo usamos una base de datos común en un cluster?
- ¿Perdemos la información de logins ante un fallo o reinicio de la aplicación?
Por lo tanto, tenemos dos problemas. Memcache no está especialmente pensado para funcionar en "modo cluster", sincronizando su contenido en n servidores; y además pierde el contenido cuando se reinicia. O sea, si tenemos que reiniciar Memcached perdemos los datos de usuarios que ya se han validado (aunque sólo sea cosa de una media hora).
Obviamente, las ventajas superan a los inconvenientes. Sin embargo, en el "mercado" tenemos una aplicación que, además de tener los pros, supera los cons: Redis, que permite un modelo master/slave, y además permite volcar periódicamente la información de memoria a disco para su recuperación en caso de caida. Es más, permite tener una especie de redo log en disco.
Bien, ya tenemos el almacén de información. ¿Cómo añadimos los datos? Usaremos cualquier aplicación de las muchas que permiten ejecutar una acción en función de haber encontrado un patrón en un log. Un ejemplo en perl es mailwatch, pero se puede usar cualquier otra. En el fondo, lo único que hay que hacer es conectarse al nodo master de Redis, y después ejecutar el comando "SETEX <host_validado> <segundos> <rcpt>".
Bien, sólo nos queda la aplicación. Necesitamos que:
- Escuche en un puerto TCP.
- Esté muy orientado a eventos.
- Tenga un muy buen rendimiento.
- Sea sencillo de programar.
Y aquí es donde aparece node.js.
node.js
Hay algo indudable en la informática de hoy en día: Cada vez está más orientada a la web. En este entorno se usan muchos lenguajes, desde php a .net; pero si hay uno que ha usado "casi" todo el mundo, ese es javascript.
Node.js es una forma de llevar javascript fuera del contexto de los navegadores web. Básicamente es una especie de wrapper para V8, el compilador de javascript de Google. Y esto es algo muy importante, porque estamos hablando de uno de los compiladores más avanzados que hay hoy en día. Evidentemente, node.js no consigue el rendimiento de C, pero supera con cierta facilidad a perl o python, todo además sin perder la familiaridad y versatilidad de javascript.
Node.js, además de usar V8, implementa algunas de las funcionalidades que hacen falta para ejecutarse fuera de un navegador, como la manipulación de datos binarios.
La otra característica de node es que está completamente orientado a eventos, y por lo tanto necesita un cierto cambio de chip por parte del programador. En node.js casi nada es síncrono: Cuando queremos acceder a un fichero, por ejemplo, en lugar de esperar a que el disco se sitúe en la posición adecuada y lea los datos, seguimos con la ejecución del programa y con el resto de eventos, hasta que los datos estén disponibles. Según Yahoo, gracias a este modelo un único procesador Xeon a 2.5GHz ejecutando un proxy inverso puede servir cerca de 2100 peticiones por segundo [2].
Dejo la instalación de node.js (y de Redis, y de mailgraph, ...) para el lector. Veamos el código de nuestro servidor:
Empezamos por la configuración de Postfix, en /etc/postfix/main.cf:
smtpd_recipient_restrictions = .... check_policy_service inet:127.0.0.1:10000 ....
Nuestro servidor va a escuchar en localhost y en el puerto 10000.
Y ahora vamos con el código, en sus 67 líneas, aunque para ser correctos, falta la mayoría de la gestión de errores:
var net = require('net');
var sys = require("sys");
var redis = require("redis");
var puertoplcy = 10000;
var hostplcy = 'localhost';
var puertoredis = 6379;
var hostredis = 'localhost';
Hemos definido las variables y las librerías que vamos a usar, incluyendo una "third party" para acceso a Redis que hemos instalado con (npm install redis).
var server = net.createServer(function (stream) {
var client = redis.createClient(puertoredis,hostredis);
client.on("error", function (err) {
sys.log("Redis error en la conexion a: " + client.host + " en el puerto: " + client.port + " - " + err);
});
stream.setEncoding('utf8');
stream.setNoDelay(true);
stream.on('connect', function () {
sys.log("Conexion nueva.");
});
stream.on('data', function (data) {
sys.log("Correo entrante:\n" + data);
var clientaddr, tmpclientaddr;
var rcpt, tmprcpt;
var datos = data.split('\n');
for (var i = 0; i < datos.length; i++ ) {
if (datos[i] && datos[i].match(/client_address=/) ) {
tmpclientaddr = datos[i].split("=");
clientaddr = tmpclientaddr[1].trim();
sys.log("Extraido el client address: " + clientaddr);
} else if (datos[i] && datos[i].match(/recipient=/) ) {
tmprcpt = datos[i].split("=");
rcpt = tmprcpt[1].trim();
sys.log("Extraido el rcpt to: " + rcpt);
}
}
client.get(clientaddr, function (err, reply) {
if (err) {
sys.log("Get error: " + err);
}
if (reply) {
sys.log("Se ha encontrado el host: " + clientaddr + " que ha usado: " + reply);
stream.write('action=ok\n\n');
} else {
sys.log("El host: " + clientaddr + " con el usuario: " + rcpt + " no se ha validado");
stream.write('action=reject 550 Relay denegado.\n\n');
}
});
});
stream.on('end', function () {
sys.log("Fin de la conexion");
stream.end();
});
});
Este es el servidor, con un poco de logueo por consola que en condiciones normales se debería quitar. Hemos definido eventos para conexiones nuevas, para cuando entran datos nuevos, ...; tenemos un callback para cuando leemos datos de Redis, .....
Al final, si tenemos el dato devolvemos un "action=ok\n\n", y si no lo tenemos pasamos un "action=reject 550 Relay denegado.\n\n", aunque esto puede variar en función de la configuración de Postfix.
Y por último, hacemos que el servidor escuche en el puerto 10000 de localhost:
server.listen(puertoplcy, hostplcy);
Y ya está. Todo esto lo guardamos en un fichero (pbs_filter.js por ejemplo), y lo ejecutamos desde una shell:
/usr/local/bin/node pbs_filter.js
Bueno, para terminar, una imagen del planteamiento:
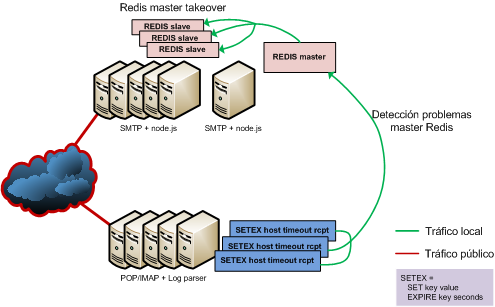
En definitiva, node.js es otro más de esos proyectos que aparecen periódicamente y que cogen cierta fuerza. Esto no es nada nuevo; hay muchos proyectos abandonados que tuvieron "su momento", pero creo que tiene ciertas características que lo hacen interesante. El tiempo dirá si tiene futuro.
Notas
| [1] | postfix tiene muy buena documentación. RTFineM. |
| [2] | Node.js, igual que Memcached y otros, no es multi-hilo. En el mismo enlace de Yahoo hay una interesante discusión sobre el uso de varios cores. |