HA
Azkeneko hamarkadetan Internet eta sare korporatiboen erabilpenak sekulako garapena izan du. Gaur egun, hainbat eta hainbat enpresek sareen eta informatikaren beharra dute, askotan erabateko menpekotasuna, bai barne funtzionamendua bai bezeroekiko harremana hauen bitartez egiten baita. Etorkizunari begira ere, joerak menpekotasun hau gero eta orokortuagoa izango dela dioenez, gero eta azpiegitura sendoagoak edo egonkorragoak eskatzen dira; hitz gutxitan, fidagarritasun handikoak.
Interneteko atariak, erosketak egiteko web guneak edo sare korporatiboak, gutxi batzuk aipatzeko, asteko zazpi egunetan hogeita lau orduz funtzionamenduan egon behar dute. Hau bete ezean, eskainitako zerbitzuak doanekoak badira ere, ondorioak kaltegarriak izango dira. Zer esanik ez merkataritza elektronikoan diharduen web gune batean, edo sare korporatiboaren menpekotasuna duen enpresa batean. Eta larrialdietarako erabiltzen den azpiegiturak arazorik balu? Eta ospitalea balitz? Hauetan, noski, fidagarritasunaren beharrak gora egiten du. Sistema baten fidagarritasun mailaren deskribapena gehienetan kontzeptualki egiten den zerbait da. Askotan, sare diagrama bat hartuta, trafikoaren ohiko fluxua zein den, azpiegituraren punturik ahulenek non dauden edo arazoen aurrean zer egin behar den irudien bitartez deskribatzen dira. Azpiatal honetan guzti honi formalismo minimo bat ematen ahaleginduko naiz, baina kalkulu matematikoetan gehiegi sartu gabe. Honela, nire ustez, praktikara erraztasunez eraman ahal izango dira hemen aipatutakoak. Gaian eta oinarri matematikoetan gehiago sakontzeko [Oggerino, 2001] liburua eta bertan aipatutako erreferentziak irakur daitezke.
Erabilitako kontzeptuak
Fidagarritasuna neurtzen denean, eta batez ere sareen fidagarritasunari dagokionean, hiru kontzeptu nagusi erabiltzen dira. Gehienetan ingeleraz erabiltzen direnez, hemen ere honela aipatuko ditut.
- MTBF (Mean time between failure): Gailu baten hutsegiteen artean igarotzen den denbora adierazteko erabiltzen da zenbaki hau. Fabrikatzailearen esku gelditzen da balio hau ematea, normalean orduetan.
- MTTF (Mean time to failure): Gailu bat lehenengo aldiz martxan jartzen denetik hutsegitea eman arte igarotzen den denbora adierazten du. Teknikoki MTBFren berdina ez bada era, askotan sinplifikazio bat egiten da. Hemen ere ez dut balio hau erabiliko.
- MTTR (Mean time to recovery): Hutsegitea ematen denetik sistema
berriz normaltasunera itzuli arte igarotako denbora. Balio honen
kalkulua egiteko kontutan izan beharrekoak:
- Detekzioa: Zenbat denbora behar da arazoa ematen denetik antzeman arte?
- Diagnostikoa: Zenbat denbora behar da arazoa zein den jakin arte?
- Konpontzea: Zenbat denbora igaro behar da arazoa konpondu arte?
Fidagarritasuna neurtzeko formula sinple hau erabiliko dugu:
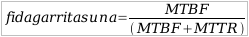
Normalean urteko fidagarritasuna da ematen den balioa, hau da, urte batean zenbat denboraz egongo den gailu bat geldituta. Urte batean 525600 minutu daudenez, zenbaki hau erabili nezakeen kalkuluak egiteko, baina bisurtetan egun bat gehiago dagoenez, askotan gainontzeko urteetan egun laurdena gehitzen da guztiak berdin gelditzeko. Hemendik aurrera 525960 zenbakia erabiliko dut salbuespenik ez idazteko, baina norberaren esku egongo da honela egitea edo ez. Praktikan, fidagarritasuna “saltzen” denean azken emaitzan zenbat 9 agertzen den esaten da. Askotan esan ohi da, eta hau ez da beti betetzen den erregela bat, bi 9tik aurrera berri bat lortu nahi den bakoitzean inbertsioa bikoiztu behar dela. Hurrengo taulan esandakoen adibide batzuk ikus daitezke:
| Bederatzi kopurua | Fidagarritasuna ehunekotan | Uptime minutuak (fidagarritasuna \* 525960) | Downtime minutuak (525960 – uptime) | Urteko downtime |
|---|---|---|---|---|
| 1 | 90.000% | 473364 | 52596 | 35.5 egun |
| 2 | 99.000% | 520700.4 | 5259.6 | 3.5 egun |
| 6 | 99.9999% | 525959.5 | 0.52596 | 32 segundo |
Hutsegite eta berreskuratze denboren analisia
Kapituluaren deskribapena egin denean, kalkulu formalegirik egingo ez nuela aipatu dut. MTBF denboran, esate baterako, erraz ikusten da fabrikatzaileak emandako datuetan erabateko ziurtasunik ez dagoela. Tenperatura desegokia, gehiegizko hautsa, hezetasuna edo, besterik ez bada, gure gailuari tokatu zaiolako; emandako MTBF balioa esandakoa baino txikiagoa izan daiteke, eta oso kontutan izan beharko genuke. Hau gutxi balitz, gehienetan sistemak konplexuak dira, hardware eta softwarearen nahasketa. Nahiz eta hardwarearen MTBF balioa eduki dezakegun, nola lortu softwareari dagokiona? Cisco-k, adibidez, bere IOSaren inguruan zenbait balio ematen ditu, baina, nola kalkulatu aldiberean exekutatzen dauden hainbat aplikazio eta protokoloren balioa, askotan erabilpen eta guztien arteko elkarrekintzaren menpe badago? Esan bezala, askotan MTBF balioa formuletan aldagai moduan utzi beharko dugu. MTTR balioa, ordea, sistemen administrazio egokiarekin hobetu ahal izango dugu. Nola gutxitu sistema bat berreskuratzeko behar dugun denbora?
- Gailuen dokumentazio ona eduki, eguneratuta. Modeloa, serie-zenbakia, software bertsioak, IP eta MAC helbideak, mantentze kontratuen informazioa....
- Ahal den neurrian mantentze kontratu onak izatea komeni da. Hogeita lau ordutako mantentze kontratu batek egun bateko MTTR balioa ematen du, gutxienez.
- Tamaina eta konplexutasun handiko saretan detekzioa eta diagnostikoa zaila izan daiteke. Ahal den neurrian azpiegitura sinple mantentzea gomendagarria da.
- Sarearen topologia, egitura, helbideratzeari buruzko informazioa edo erabilitako protokoloek arazoen aurrean portaera desberdina izan dezakete.
- Aurrekontua mugatua denean, lehentasunak jarri behar dira. Azpiegitura batean gailurik garrantzitsuenak zeintzuk diren ezagutu, eta horien gainean monitorizazio eta arazoen detekziorako sistemak ezarri.
Hauekin batera, hutsegite bat ematen denean zenbait datu jasotzea ere interesgarria izan daiteke. Nagios bezalako tresnak lagungarri izango zaizkigu honetarako:
- Hutsegitea erabatekoa edo partziala izan den.
- Hutsegitearen izaera, detekzioa eta diagnostikoa egin arte zenbat denbora igaro den.
- Hutsegitea noiz hasi den.
- Hutsegitea noiz bukatu den, hots, gailu, edo orokorrean, azpiegitura, noiz itzuli den ohiko egoerara. Askotan arazoa konponduta badago ere zerbitzari edo gailu desberdinek denbora behar dute egoera berreskuratzeko. Bideratze protokoloek, esate baterako, bideratze taulak berregiteko konbergentzia denbora deritzona behar dute berriz funtzionamendu egokia lortzeko.
Denboran zehar gertatutako datu guzti hauen analisiak detekzioan arazorik badagoen, gailurik arriskutsuenak zeintzuk diren eta berreskuratze prozesuak hobetzeko aukera emango digu, sistemaren MTTR balioa txikituz.
Fidagarritasunaren kalkuluaren aplikazioa
Gogoratu dezagun fidagarritasunaren kalkulurako erabiliko dugun formula:
Azken finean, esan genezake sistema bat funtzionamenduan dagoen denbora eta denbora osoaren arteko erlazio bat egiten ari garela goiko formulan. Modu honetan ere adierazi genezake:
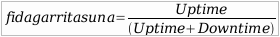
Bi kasuetan, gure azpiegituraren fidagarritasun maila igotzeko, batetik MTBF edo sistema funtzionamenduan dagoen denbora handitu, eta bestetik sistema berreskuratzeko behar den denbora txikitu beharko genuke. Web zerbitzari batean, adibidez, MTBF balioa handitzeko kalitateko hardwarea erabiliko genuke, erredundantzia eta RAID bezalakoak erabiliz. Softwareari dagokionean, sistema eragileak eta aplikazioak ere optimizatuko genituzke, mantentze, eguneraketa edo segurtasun politika egokiekin, besteak beste. MTTR balioa txikitzeko dagoeneko zenbait ideia eman ditugu. Detekzioa hobetzeko tresna egokiak erabiltzea ezinbestekoa da, diagnostiko azkarra egiteko azpiegituraren osagaiak ezagutu behar dira, formazio egokiarekin, eta apurtutakoa konpontzeko mantentze kontratu egokiak, hardwarearen kasuan, eta berreskuratze prozedura eta segurtasun kopien erabilpenarekin software arazoa denean.
Sare azpiegituraren fidagarritasuna
Sare azpiegitura bat diseinatzen denean gailu desberdinen kokapenak garrantzi handia du. Sistema fidagarri bat lortzeko ideia nagusia erredundantzia dela esan genezake. Honela, makina bat hondatzen denean, edo aplikazioren batean arazoren bat dagoenean, sistemaren gainontzeko osagaien artean hondatutako horren lana egingo litzateke. Arazoen antzematea eta berreskuratzea erabat automatikoa izatea lortuko bagenu, sistemak bere osotasunean fidagarritasun balio ona izango luke. Zoritxarrez, askotan ezin da erabateko erredundantzia duen azpiegiturarik lortu, aurrekontua mugatua izaten delako edo teknikoki konplexutasun handiegia dakarrelako.
Seriean konektatutako gailuen fidagarritasuna
Hurrengo irudian seriean konektatutako gailuekin eraikitako sare bat ikusten da:

Irudian ikusten denez, bideragailua , suhesia edo switch-a hondatuko balira sarea erabat geldituko litzateke. Erraz ikusten da hau ez dela bilatzen den egoera. Fidagarritasunaren kalkulua azpiegitura mota honekin:

Bideragailuaren fidagarritasuna 99.99% balitz, suhesiarena 99.93% eta switch-arena 99.9998%, orduan sarearena:
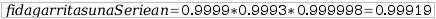
Paraleloan konektatutako gailuen fidagarritasuna
Hurrengo irudian paraleloan konektatutako gailuekin osatutako sarea ikusi daiteke:
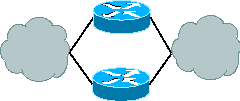
Kasu honetan bideragailu bat matxuratuko balitz bigarrena erabiliko litzateke. Protokolo egokiak erabilita, gainera, prozesu hau gardena eta ia denbora errealean eman daiteke. Zalantzarik gabe, honelako sistemak dira gehien interesatzen zaizkigunak, beti ere aurrekontuak ahalbideratzen duenean. Erabiltzen den formula:

Formularen aplikazioa irudiko kasuan eta bideragailu bakoitzaren fidagarritasuna 99.99%koa balitz:
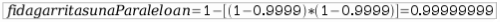
Kontutan izan honelako diseinuek sareari erredundantzia handia gehitzen badiote ere konplexutasuna ere gehitzen diotela, eta honek eragina izan dezakeela MTBF eta MTTR balioetan. Honelako sistema bat martxan jarri aurretik gomendagarria da probak egitea, kableak askatuz, gailuak itzaliz, ....
Serie eta paralelo nahasketak
Paraleloan erabat konektatutako sareak ez dira askotan ikusten. Gehienetan sarerik aurreratuenetan ere badago seriean konektatutako zerbait. Zenbaitetan makina guztiak bikoiztuta izatea garestiegia da (aterako zaion etekinarekin alderatuta), beste batzuetan honelako azpiegituren ezarketa eta mantentzeak eskatzen duen ordu kopurua handiegia da. Tarteko konponbide bat seriean eta paraleloan dauden gailuak nahastea da; honela azpiegituraren atalik garrantzitsuenak bikoizturik, eta garrantzi gutxiagokoak edo erraz ordezka daitezkeenak seriean jartzen dira.
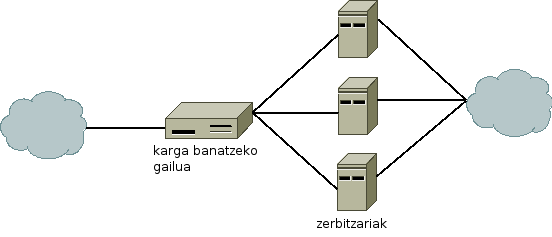
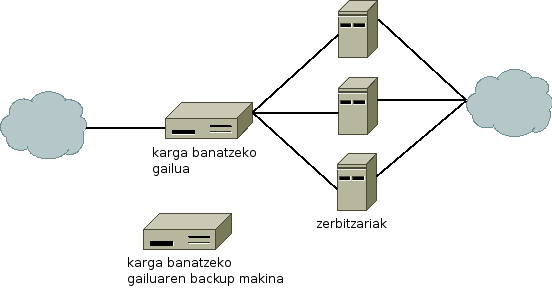
Azpiegitura zati honetan karga banatzeko gailua erredundantziarik gabe dago, zerbitzariak, berriz, paraleloan. Honen fidagarritasunaren kalkulua zatika egiten da. Lehenengo pausoan makina bakoitzaren fidagarritasuna lortzen da. Bigarren pausoan paraleloan dauden osagaien fidagarritasuna kalkulatzen da, eta azkeneko pausoan seriean dauden osagaiena. Irudiko adibidea hartuz:
Karga banatzeko gailuaren fidagarritasuna: 95%
Zerbitzari bakoitzaren fidagarritasuna: 80%
Paraleloan dauden osagaien fidagarritasuna:
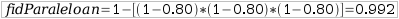
Azpiegituraren fidagarritasuna:
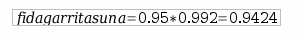
Bestelako neurriak, N + M fidagarrtasun paraleloa
Zoritxarrez, askotan sistema guztiz paraleloak garestiegiak dira. Batzuetan honen arrazoia ez da gailuak ordaindu behar izatea, baizik eta honelako sareak funtzionamenduan izateko protokolo, konfigurazio eta mantentze konplexuak behar direla. Arazo honen aurrean, N + 1 (orokorrean N + M) kontzeptua erabiltzen da. Funtsean, honekin esaten dena da gailu bat (+1) prest izango dugula beste baten tokia hartzeko.
Egoera honetan karga banatzeko sistemaren kopia bat izango dugu, N + 1 beraz. Karga banatzeko gailua matxuratuko balitz gure esku egongo litzateke backup-a bere ordez jartzea. Honek MTTR balioa sistema automatikoena baino askoz altuago izatea dakar, baina konfiguratzeko errazagoa da. N + 1 sistemen fidagarritasunaren kalkulua formula honekin egiten da:

Kalkuluak egiten baditugu:
Karga banatzeko gailu bakoitzaren fidagarritasuna: 95%
Zerbitzari bakoitzaren fidagarritasuna: 80%
Karga banatzeko N+1 sistemaren fidagarritasuna:
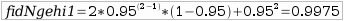
Paraleloan dauden osagaien fidagarritasuna:
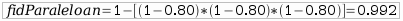
Azpiegituraren fidagarritasuna:
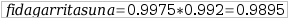
Ondorioak
Hemen fidagarritasuna neurtzeko metodo baten azaleko deskribapena egin dut. Metodoa baino, kalkuluak eta lortutako balioak baino, gehiago interesatzen zait sistema baten fidagarritasunean eragina duten faktoreak ezagutzea. Guzti honekin, edozein enpresatan fidagarritasuna hobetzeko plangintza zehaztasunaz egin ahal izango dugu. Honela, fase batean MTBF balioa hobetzeko sistema eragile edo aplikazio sendoagoak instalatzea pentsa genezake, beste batean detekziorako sistema eta berreskuratze prozedurak indartzea MTTR baliorako, beste batean backup makinak, edo seriean dauden gailuak paraleloan jartzea. Fase bakoitzean, gainera, hobekuntzen azalpen formala egiteko aukera izango genuke.